
Research News



New virtual reality-tested system shows promise in aiding navigation of people with blindness or low vision
A new study offers hope for people who are blind or have low vision (pBLV) through an innovative navigation system that was tested using virtual reality. The system, which combines vibrational and sound feedback, aims to help users navigate complex real-world environments more safely and effectively.
The research from NYU Tandon School of Engineering, published in JMIR Rehabilitation and Assistive Technology, advances work from John-Ross Rizzo, Maurizio Porfiri and colleagues toward developing a first-of-its-kind wearable system to help pBLV navigate their surroundings independently.
“Traditional mobility aids have key limitations that we want to overcome,” said Fabiana Sofia Ricci, the paper’s lead author and a Ph.D. candidate in NYU Tandon Department of Biomedical Engineering (BME) and NYU Tandon’s Center for Urban Science + Progress (CUSP). “White canes only detect objects through contact and miss obstacles outside their range, while guide dogs require extensive training and are costly. As a result, only 2 to 8 percent of visually impaired Americans use either aid.”
In this study, the research team miniaturized the earlier haptic feedback of its backpack-based system into a discreet belt equipped with 10 precision vibration motors. The belt's electronic components, including a custom circuit board and microcontroller, fit into a simple waist bag, a crucial step toward making the technology practical for real-world use.
The system provides two types of sensory feedback: vibrations through the belt indicate obstacle location and proximity, while audio beeps through a headset become more frequent as users approach obstacles in their path.
"We want to reach a point where the technology we’re building is light, largely unseen and has all the necessary performance required for efficient and safe navigation," said Rizzo, who is an associate professor in NYU Tandon’s BME department, associate director of NYU WIRELESS, affiliated faculty at CUSP and associate professor in the Department of Rehabilitation Medicine at NYU Grossman School of Medicine.
"The goal is something you can wear with any type of clothing, so people are not bothered in any way by the technology."
The researchers tested the technology by recruiting 72 participants with normal vision, who wore Meta Quest 2 VR headsets and haptic feedback belts while walking around NYU's Media Commons at 370 Jay Street in Downtown Brooklyn, an empty room with only side curtains.
Through their headsets, the participants experienced a virtual subway station as someone with advanced glaucoma would see it - with reduced peripheral vision, blurred details, and altered color perception. The environment, created with Unity gaming software to match the room's exact dimensions, allowed the team to determine how well participants could navigate using the belt's vibrations and audio feedback when their vision was impaired.

"We worked with mobility specialists and NYU Langone ophthalmologists to design the VR simulation to accurately recreate advanced glaucoma symptoms," says Porfiri, the paper’s senior author, CUSP Director and an Institute Professor in NYU Tandon’s Departments of BME and Mechanical and Aerospace Engineering. "Within this environment, we included common transit challenges that visually impaired people face daily - broken elevators, construction zones, pedestrian traffic, and unexpected obstacles."
Results showed that haptic feedback significantly reduced collisions with obstacles, while audio cues helped users move more smoothly through space. Future studies will involve individuals with actual vision loss.
The technology complements the functionality of Commute Booster, a mobile app being developed by a Rizzo-led team to provide pBLV navigation guidance inside subway stations. Commute Booster “reads” station signage and tells users where to go, while the haptic belt could help those users avoid obstacles along the way.
In December 2023, the National Science Foundation (NSF) awarded Rizzo, Porfiri, and a team of NYU colleagues a $5 million grant via its Convergence Accelerator, a program whose mission includes supporting the development of assistive and rehabilitative technologies. That grant, along with others from NSF, funded this research and also supports Commute Booster’s development. In addition to Ricci, Rizzo and Porfiri, Lorenzo Liguori and Eduardo Palermo are the paper’s authors, both from the Department of Mechanical and Aerospace Engineering of Sapienza University of Rome, Italy.
Ricci F, Liguori L, Palermo E, Rizzo J, Porfiri M
Navigation Training for Persons With Visual Disability Through Multisensory Assistive Technology: Mixed Methods Experimental Study
JMIR Rehabil Assist Technol 2024;11:e55776
DOI: 10.2196/55776

Out of thin air: Researchers create microchips capable of detecting and diagnosing diseases
In a world grappling with a multitude of health threats — ranging from fast-spreading viruses to chronic diseases and drug-resistant bacteria — the need for quick, reliable, and easy-to-use home diagnostic tests has never been greater. Imagine a future where these tests can be done anywhere, by anyone, using a device as small and portable as your smartwatch. To do that, you need microchips capable of detecting miniscule concentrations of viruses or bacteria in the air.
Now, new research from NYU Tandon faculty including Professor of Electrical and Computer Engineering Davood Shahrjerdi; Herman F. Mark Professor in Chemical and Biomolecular Engineering Elisa Riedo; and Giuseppe de Peppo, Industry Associate Professor in Chemical and Biomolecular Engineering and who was previously at Mirimus, shows it’s possible to develop and build microchips that can not only identify multiple diseases from a single cough or air sample, but can also be produced at scale.
“This study opens new horizons in the field of biosensing. Microchips, the backbone of smartphones, computers, and other smart devices, have transformed the way people communicate, entertain, and work. Similarly, today, our technology will allow microchips to revolutionize healthcare, from medical diagnostics, to environmental health” says Riedo,
“The innovative technology demonstrated in this article uses field-effect transistors (FETs) — miniature electronic sensors that directly detect biological markers and convert them into digital signals — offering an alternative to traditional color-based chemical diagnostic tests like home pregnancy tests,” said Shahrjerdi. “This advanced approach enables faster results, testing for multiple diseases simultaneously, and immediate data transmission to healthcare providers” says Sharjerdi, who is also the Director of the NYU Nanofabrication Cleanroom, a state-of-the-art facility where some of the chips used in this study were fabricated. Riedo and Shahrjerdi are also the co-directors of the NYU NanoBioX initiative.
Field-effect transistors, a staple of modern electronics, are emerging as powerful tools in this quest for diagnostic instruments. These tiny devices can be adapted to function as biosensors, detecting specific pathogens or biomarkers in real time, without the need for chemical labels or lengthy lab procedures. By converting biological interactions into measurable electrical signals, FET-based biosensors offer a rapid and versatile platform for diagnostics.
Recent advancements have pushed the detection capabilities of FET biosensors to incredibly small levels — down to femtomolar concentrations, or one quadrillionth of a mole — by incorporating nanoscale materials such as nanowires, indium oxide, and graphene. Yet, despite their potential, FET-based sensors still face a significant challenge: they struggle to detect multiple pathogens or biomarkers simultaneously on the same chip. Current methods for customizing these sensors, such as drop-casting bioreceptors like antibodies onto the FET’s surface, lack the precision and scalability required for more complex diagnostic tasks.
To address this, these researchers are exploring new ways to modify FET surfaces, allowing each transistor on a chip to be tailored to detect a different biomarker. This would enable parallel detection of multiple pathogens.
Enter thermal scanning probe lithography (tSPL), a breakthrough technology that may hold the key to overcoming these barriers. This technique allows for the precise chemical patterning of a polymer-coated chip, enabling the functionalization of individual FETs with different bioreceptors, such as antibodies or aptamers, at resolutions as fine as 20 nanometers. This is on par with the tiny size of transistors in today’s advanced semiconductor chips. By allowing for highly selective modification of each transistor, this method opens the door to the development of FET-based sensors that can detect a wide variety of pathogens on a single chip, with unparalleled sensitivity.
Riedo, who was instrumental in the development and proliferation of tSPL technology, sees its use here to be further evidence of the groundbreaking way this nanofabrication technique can be used in practical applications. “tSPL, now a commercially available lithographic technology, has been key to functionalize each FET with different bio-receptors in order to achieve multiplexing,” she says.
In tests, FET sensors functionalized using tSPL have shown remarkable performance, detecting as few as 3 attomolar (aM) concentrations of SARS-CoV-2 spike proteins and as little as 10 live virus particles per milliliter, while effectively distinguishing between different types of viruses, including influenza A. The ability to reliably detect such minute quantities of pathogens with high specificity is a critical step toward creating portable diagnostic devices that could one day be used in a variety of settings, from hospitals to homes.
The study, now published by the Royal Society of Chemistry in Nanoscale, was supported by Mirimus, a Brooklyn-based biotechnology company, and LendLease, a multinational construction and real estate company based in Australia. They are working with the NYU Tandon team to develop illness-detecting wearables and home devices, respectively.
“This research shows off the power of the collaboration between industry and academia, and how it can change the face of modern medicine,” says Prem Premsrirut, President and CEO of Mirimus. “NYU Tandon’s researchers are producing work that will play a large role in the future of disease detection.”
“Companies such as Lendlease and other developers involved in urban regeneration are searching for innovative solutions like this to sense biological threats in buildings.” says Alberto Sangiovanni Vincentelli of UC Berkeley, a collaborator on the Project. “Biodefense measures like this will be a new infrastructural layer for the buildings of the future”
As semiconductor manufacturing continues to advance, integrating billions of nanoscale FETs onto microchips, the potential for using these chips in biosensing applications is becoming increasingly feasible. A universal, scalable method for functionalizing FET surfaces at nanoscale precision would enable the creation of sophisticated diagnostic tools, capable of detecting multiple diseases in real time, with the kind of speed and accuracy that could transform modern medicine.

Discovery of new growth-directed graphene stacking domains may precede new era for quantum applications
Graphene, a single layer of carbon atoms arranged in a two-dimensional honeycomb lattice, is known for its exceptional properties: incredible strength (about 200 times stronger than steel), light weight, flexibility, and excellent conduction of electricity and heat. These properties have made graphene increasingly important in applications across various fields, including electronics, energy storage, medical technology, and, most recently, quantum computing.
Graphene’s quantum properties, such as superconductivity and other unique quantum behaviors, are known to arise when graphene atomic layers are stacked and twisted with precision to produce “ABC stacking domains.” Historically, achieving ABC stacking domains required exfoliating graphene and manually twisting and aligning layers with exact orientations—a highly intricate process that is difficult to scale for industrial applications.
Now, researchers at NYU Tandon School of Engineering led by Elisa Riedo, Herman F. Mark Professor in Chemical and Biomolecular Engineering, have uncovered a new phenomenon in graphene research, observing growth-induced self-organized ABA and ABC stacking domains that could kick-start the development of advanced quantum technologies. The findings, published in a recent study in the Proceedings of the National Academy Of Sciences (PNAS), demonstrate how specific stacking arrangements in three-layer epitaxial graphene systems emerge naturally — eliminating the need for complex, non-scalable techniques traditionally used in graphene twisting fabrication.
These researchers, including Martin Rejhon, previously a post-doctoral fellow at NYU, have now observed the self-assembly of ABA and ABC domains within a three-layer epitaxial graphene system grown on silicon carbide (SiC). Using advanced conductive atomic force microscopy (AFM), the team found that these domains form naturally without the need for manual twisting or alignment. This spontaneous organization represents a significant step forward in graphene stacking domains fabrication.
The size and shape of these stacking domains are influenced by the interplay of strain and the geometry of the three-layer graphene regions. Some domains form as stripe-like structures, tens of nanometers wide and extending over microns, offering promising potential for future applications.
“In the future we could control the size and location of these stacking patterns through pregrowth patterning of the SiC substrate,” Riedo said.
These self-assembled ABA/ABC stacking domains could lead to transformative applications in quantum devices. Their stripe-shaped configurations, for example, are well-suited for enabling unconventional quantum Hall effects, superconductivity, and charge density waves. Such breakthroughs pave the way for scalable electronic devices leveraging graphene's quantum properties.
This discovery marks a major leap in graphene research, bringing scientists closer to realizing the full potential of this remarkable material in next-generation electronics and quantum technologies.
The funding for this research came from the Army Research Office, a directorate of U.S. Army Combat Capabilities Development Command Army Research Laboratory under Award # W911NF2020116. This research also included researchers from Charles University, Prague.

Self-assembling proteins can be used for higher performance, more sustainable skincare products
If you have a meticulous skincare routine, you know that personal skincare products (PSCPs) are a big business. The PSCP industry will reach $74.12 billion USD by 2027, with an annual growth rate of 8.64%. With such competition, companies are always looking to engineer themselves an edge, producing products that perform better without the downsides of current offerings.
In a new study published in ACS Applied Polymer Materials from the lab of Professor of Chemical and Biomolecular Engineering Jin Kim Montclare, researchers have created a novel protein-based gel as a potential ingredient in sustainable and high-performance PSCPs. This protein-based material, named Q5, could transform the rheological — or flow-related — properties of PSCPs, making them more stable under the slightly acidic conditions of human skin. This innovation could also streamline the creation of more eco-friendly skincare products, offering increased efficacy and durability while addressing market demands for ethically sourced ingredients.
Personal skincare products, ranging from beauty cosmetics to medical creams, rely on sophisticated “chassis” formulations — often emulsions or gels — to effectively deliver active ingredients. The performance of these products depends heavily on the stability and responsiveness of their chassis under various environmental conditions, particularly pH.
Current formulations often rely on ingredients such as polysaccharides or synthetic polymers to achieve the desired texture, stability, and compatibility with skin's natural pH, which is mildly acidic (most human skin has a pH of between 5.4–5.9). However, these traditional rheological modifiers have raised environmental concerns regarding sourcing and sustainability.
To take on this challenge, Montclare and her colleagues fabricated a self-assembling coiled-coil protein they call Q5. In the study, Q5 demonstrated impressive pH stability. The protein's unique structure enables it to form strong gels that do not degrade easily under acidic conditions, enhancing the longevity and performance of skincare products.This resilience marks a significant improvement over earlier protein-based gels, which typically disassemble in lower pH environments.
Notably, the research suggests that Q5 could be produced sustainably via bacterial or yeast fermentation, circumventing the ethical and ecological issues associated with animal-derived proteins or synthetic polymers. The protein’s natural amphiphilicity — its ability to attract and retain moisture — also enables it to bind various molecules, adding versatility as a moisturizer or binding agent in skincare products.
The research suggests that these protein-based rheological modifiers like Q5 could soon become a valuable component in the next generation of high-performance skincare products, helping brands meet consumer demand for sustainable beauty solutions without compromising on quality or functionality.
Britton, D., Sun, J., Faizi, H. A., Yin, L., Gao, W., & Montclare, J. K. (2024). Recombinant fibrous protein gels as rheological modifiers in skin ointments. ACS Applied Polymer Materials, 6(20), 12832–12841. https://doi.org/10.1021/acsapm.4c02468

New study tracks leptin pulse patterns, a potential clue to understanding obesity
Obesity has become a global epidemic, and the need for treatment and monitoring for people with obesity is growing. Researchers aiming to understand relevant biomarkers for the condition have fixed their gaze on leptin, a hormone that regulates energy intake and induces feelings of fullness, to eventually help improve treatments for obesity. Understanding the patterns of leptin secretion from fat cells throughout the body could help scientists identify hidden health issues in patients with obesity, monitor health development after treatment, and test drug effectiveness.
Now, in a new study in the Journal of the Endocrine Society, NYU Tandon Associate Professor of Biomedical Engineering Rose Faghih and her PhD students Qing Xiang and Revanth Reddy have utilized a probabilistic physiological modeling approach to investigate the pulse events underlying leptin secretion.
“Instead of only relying on visual inspection of leptin by statistical modeling of leptin secretion events, we quantify the underlying pulsatile physiological signaling to enable extending investigations of leptin signaling in health and disease and in response to medications,” said Faghih.
Leptin, produced primarily by fat cells, typically signals the brain when enough food has been consumed, helping to regulate energy and appetite. But in some individuals with obesity, this signaling system seems to malfunction — a condition known as leptin resistance, where high levels of leptin fail to curb hunger. Why this resistance develops remains unclear, but recent findings on leptin’s high-frequency, wave-like release patterns offer intriguing possibilities for future research.
Hormones like cortisol and insulin, which manage stress and blood sugar, are known to follow rhythmic release patterns, adapting to daily cycles. Leptin follows a similar — but unknown
— rhythm. Faghih’s lab set out to analyze leptin’s pulses, examining how often these leptin pulses occur and their relative strength. By breaking down the pulses into their timings and amplitudes, researchers could better understand these patterns, which could lead to breakthroughs in treating leptin resistance and, by extension, obesity.
The researchers applied statistical models with different complexities to fit the data and compared the performance of these distribution models for each subject using pre-established metrics. They aimed to find the best model for these distributions which would be important in monitoring leptin secretion and detecting deviations from a normal secretion pattern.
The results show that each of these models can capture the general shape of the distribution alone for each subject despite the complex process of leptin secretion which can be affected by various factors. These distribution models suggest several possible features of leptin secretion such as the rarity of extremely small or large pulses.
They also allow researchers to see the effects of drugs by identifying changes in the model parameters before and after treatment. They compared leptin behavior before and after treatment with bromocriptine, a medication that affects neuroendocrine signaling. After treatment, subtle shifts in one model of leptin’s pulse timings (the diffusion model) suggested that it might be possible to influence these patterns with medication. Such findings open the door to exploring hormonal treatments for obesity that work by reestablishing leptin’s natural rhythms.
The research is a key first step in reliable long term leptin monitoring that could help doctors and patients fight obesity.
This work was supported by the National Institutes of Health (NIH) under grant R35GM151353: MESH: Multimodal Estimators for Sensing Health.
Qing Xiang, Revanth Reddy, Rose T Faghih, Marked Point Process Secretory Events Statistically Characterize Leptin Pulsatile Dynamics, Journal of the Endocrine Society, Volume 8, Issue 10, October 2024, bvae149, https://doi.org/10.1210/jendso/bvae149
NYC's ride-hailing fee failed to ease Manhattan traffic, new NYU Tandon study reveals
New York City's 2019 ride-hailing surcharge cut overall taxi and ride-share trips by 11 percent in Manhattan but failed to reduce traffic congestion, a key goal of the policy, according to a new NYU Tandon School of Engineering study published in Transportation Research Part A.
“While this surcharge differs from the MTA's proposed congestion pricing plan, the study's findings can contribute to the current discourse,” said Daniel Vignon — assistant professor of Civil and Urban Engineering (CUE) and member of C2SMARTER, a U.S. Department of Transportation Tier 1 University Transportation Center — who led the research with CUE PhD student Yanchao Li. “Indeed, the research reveals how pricing policies can disproportionately affect different communities and emphasizes that accessible transit alternatives play a crucial role in shaping how such policies impact travel behavior.”
Using a Difference-in-Differences framework — a statistical method that compares changes in outcomes between locations subject to a policy and those that are not — researchers isolated the impact of the $2.50 to $2.75 fee imposed below 96th Street by analyzing patterns both inside and outside the surcharge zone, while also comparing the same areas before and after the policy took effect.
"We were not necessarily surprised by the findings," explained Vignon. "The City claims that Uber, Lyft and taxis increase congestion, but we would say that they are not the major contributors," noting that research from other cities has also found ride-hailing services don't significantly contribute to traffic congestion. “In general, most cities experience a reduction in travel speed between 2% to 8% following the entry of Uber/Lyft.”
While traffic speeds remained virtually unchanged after the surcharge, Lyft experienced a 17 percent decrease in trips, and Uber and yellow cabs saw drops of 9 percent and 8 percent respectively, the research showed.
The policy's impact varied based on available transportation alternatives. Areas without subway or Citi Bike access saw only a 1.6 percent reduction in rides, while neighborhoods with both options experienced a 7.4 percent decrease. Areas with Citi Bike alone showed a 6.8 percent reduction.
The study revealed a complex relationship between income and transit access. Higher-income neighborhoods, despite typically having better transit options, showed minimal reduction in ride-hailing use. In contrast, lower-income areas saw sharp declines even though they often had fewer transit alternatives.
"When policymakers plan for any type of congestion pricing, it's critical they account for the alternative transportation options available at a granular level. A policy that works well in one neighborhood may impose a very high cost in areas where people live with far fewer resources and choices," said Vignon, noting that the street-hailing industry saw an 8 percent decrease in revenue after implementation. “It seems that this policy resulted in a net welfare loss for the city, at least in the shorter term, when considering all factors, such as abandoned rides and the decrease in driver revenues. In the longer term, to determine whether the policy is a net positive, one would have to account for how the collected fees are spent.”
This study is part of Vignon’s body of work examining how regulatory policies affect transportation systems. His research interests span ride-hailing regulations, autonomous vehicles, and infrastructure investment, analyzing how agencies can improve system performance while considering that users and transportation service providers will adapt their behavior based on policy changes.
The research also contributes to the portfolio of C2SMARTER, a consortium of seven universities led by NYU Tandon that is pursuing an ambitious research, education, training, and technology transfer program agenda to address the U.S. DOT priority area of Congestion Reduction. It received its most recent Tier 1 UTC designation in early 2023, providing it $15 million in funding for five years and extending its first such designation that came in 2016.
In this study, Vignon and Li analyzed over 300,000 ride-hailing records from NYC's Taxi and Limousine Commission, along with nearly 1 million traffic speed measurements from Uber Movement, incorporating data from Citi Bike, subway locations, household income statistics, and weather patterns.
Yanchao Li, Daniel Vignon, Do ride-hailing congestion fees in NYC work?, Transportation Research Part A: Policy and Practice,
Volume 190, 2024, 104274,
ISSN 0965-8564 https://doi.org/10.1016/j.tra.2024.104274.

NYU Tandon researchers uncover security flaw in miniature medical labs
NYU researchers have identified a new material-level security risk in an emerging medical technology known as labs-on-chips, miniature devices that perform multiple laboratory tests on tiny fluid samples like blood droplets.
A team led by NYU Abu Dhabi and the NYU Center for Cybersecurity (CCS) found that in one type of these devices, called flow-based microfluidic biochips (FMBs), the crucial microscopic valves responsible for controlling the fluid flow could be subtly altered at the material level by doping reactive chemicals or stealthily altering the chemical composition during manufacturing. These microvalves are critical for the integrated microfluidic circuitry, as they precisely manipulate fluids for a bio-protocol via deforming under pneumatic pressure.
The researchers found that stealthy tampering can be achieved by introducing harmful chemicals or by altering the associated chemical composition, which significantly changes the energetics of the microvalve deformation. The tampered valves look normal under a microscope but can be triggered to rupture when exposed to deliberate low-frequency pneumatic actuations.
In a study published in Scientific Reports, the researchers name these bad valves "BioTrojans.”
"Material-level cyber-physical attacks on biochips remain understudied, posing significant future security risks,” said Navajit Singh Baban, a CCS postdoctoral associate and the study's lead author. “In this study, we've shown that by simply changing the ratio of ingredients used to make certain valves, we can create a ticking time bomb within the device. These BioTrojans look identical to normal valves but behave very differently under stress."
The researchers demonstrated that valves made with altered ratios of a common polymer called polydimethylsiloxane (PDMS) could rupture within seconds when subjected to pneumatic actuations. In contrast, properly manufactured valves withstood the same conditions for days without failure.
The implications of such vulnerabilities are significant. Microfluidic biochips are increasingly used in critical applications such as disease diagnosis, DNA analysis, drug discovery, and biomedical research. A compromised valve could lead to contamination, inaccurate test results, or complete device failure, potentially endangering patients or derailing important research.
"This isn't just about a malfunctioning medical device," said Ramesh Karri, the senior author of the study. Karri is a professor and chair of NYU Tandon School of Engineering’s Electrical and Computer Engineering Department and a member of CCS, which he co-founded in 2009. "It's about the potential for malicious actors to intentionally sabotage these critical tools in ways that are very difficult to detect.”
The research team’s proposed solutions include design modifications to make valves more resilient and a novel authentication method using fluorescent dyes to detect tampered components.
"We're entering an age where the line between the digital and biological worlds is blurring," Baban said. "As these miniaturized labs become more prevalent in healthcare settings, ensuring their security will be crucial to maintaining trust in these potentially life-saving technologies. We hope this work will spur further investigation into the cybersecurity aspects of biomedical devices and lead to more robust safeguards in their design and manufacture.”
In addition to Baban and Karri, the paper's authors are Jiarui Zhou, Kamil Elkhoury, Yong-Ak Song and Sanjairaj Vijayavenkataraman, all from the Division of Engineering at NYU Abu Dhabi; Nikhil Gupta, professor in NYU Tandon’s Department of Mechanical and Aerospace Engineering and member of CCS; Sukanta Bhattacharjee from the Department of Computer Science and Engineering at Indian Institute of Technology Guwahati; and Krishnendu Chakrabarty from the School of Electrical, Computer and Energy Engineering at Arizona State University.
Baban, N.S., Zhou, J., Elkhoury, K. et al. BioTrojans: viscoelastic microvalve-based attacks in flow-based microfluidic biochips and their countermeasures. Sci Rep 14, 19806 (2024). https://doi.org/10.1038/s41598-024-70703-0
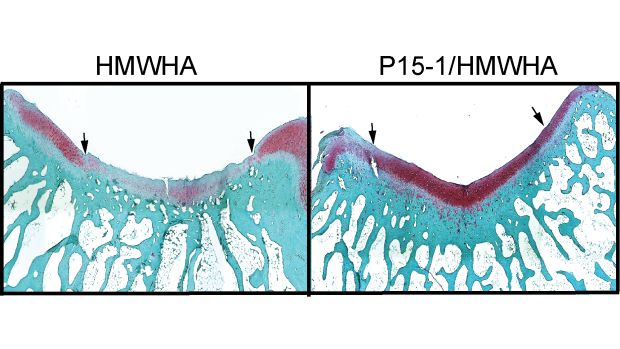
Revolutionizing cartilage repair: The role of macrophages and hyaluronic acid in healing injuries
Injuries of the knee resulting in damage to cartilage affect approximately 900,000 Americans annually, resulting in more than 200,000 surgical procedures. These injuries are frequently associated with pain, diminished joint functionality, and reduced life quality. In addition, these traumatic joint injuries lead to the early onset of post traumatic osteoarthritis, requiring eventual joint replacement. Joint replacement, especially at relatively young age, results in significant limitations to lifestyle and potential complications, including the limited lifespan of the implants.
Now, a new study from Professors of Biomedical Engineering and Orthopaedic Surgery Mary Cowman and Thorsten Kirsch is promising a novel solution to the issue of inflammation in such injuries, in order to promote healthy healing and prevent the need for more invasive procedures and treatments.
A key factor in the complex repair process is the body’s immune response, particularly the role of macrophages, which are immune cells that play a crucial role in inflammation following joint injury. After injury, these cells can adopt different states — pro-inflammatory and anti-inflammatory — that need to be in balance for proper repair.
Pro-inflammatory macrophages drive inflammation by releasing pro-inflammatory cytokines, which can inhibit the proliferation and viability of mesenchymal stem cells (MSCs)—cells essential for cartilage regeneration. This not only limits MSC function but also hampers their ability to modulate the immune environment and differentiate into chondrocytes, the cells responsible for cartilage formation. This can lead to chronic inflammation and the onset of post-traumatic osteoarthritis. The challenge is rebalancing these macrophages to support the anti-inflammatory varieties.
Recent research has uncovered a pivotal role for hyaluronic acid (aka hyaluronan, HA), a glycosaminoglycan found in the extracellular matrix of tissues like cartilage, in this immune modulation. While HA plays a critical role in normal cartilage tissue structure and function, and is widely used to alleviate pain in osteoarthritis, it can be degraded in inflamed tissues. Degraded HA interacts with a protein receptor known as RHAMM (Receptor for Hyaluronan-Mediated Motility), which is minimally expressed in healthy adult tissues but becomes highly upregulated following injury. While RHAMM interactions with HA are essential for processes like cell migration and tissue repair, they also contribute to inflammation and fibrosis in various pathological conditions.
Cowman and Kirsch’s new study tested the effects of disrupting these interactions, by using a synthetic peptide known as P15-1, which mimics RHAMM and competes with it for HA binding, in combination with natural high molecular weight HA. In a rabbit model for cartilage defect repair, the therapeutic formulation effectively shifts the balance of macrophages to the anti-inflammatory state, and improves healing while limiting damage.
These findings could hold promise for improving cartilage repair outcomes, offering a way to break the cycle of inflammation and promote more effective healing. As the field of regenerative medicine continues to evolve, targeting immune pathways like HA-RHAMM interactions may open new avenues for treating joint injuries and preventing the long-term consequences of post-traumatic osteoarthritis.
This work was supported by the NIH and by a grant from The Ines Mandl Research Foundation. The Ines Mandl Research Foundation (IMRF) is dedicated to providing research funding in the fight against connective tissue disease. It is the legacy of Dr. Ines Mandl (TANDON ’47, ’49), who was the first woman to graduate from the Polytechnic Institute of Brooklyn—today’s NYU Tandon School of Engineering—with a PhD in chemistry in 1949.
Bianchini, E. Sin, Y.J.A., Lee, Y.J., Lin, C., Anil, U., Hamill, C., Cowman, M.K., Kirsch, T. (2024) “The Role of Hyaluronan/RHAMM Interactions in the Modulation of Macrophage Polarization and Cartilage Repair” Am.J.Pathology 194, 1047-1061, https://doi.org/10.1016/j.ajpath.2024.01.020

New tool helps analyze pilot performance and mental workload in augmented reality
In the high-stakes world of aviation, a pilot's ability to perform under stress can mean the difference between a safe flight and disaster. Comprehensive and precise training is crucial to equip pilots with the skills needed to handle these challenging situations.
Pilot trainers rely on augmented reality (AR) systems for teaching, by guiding pilots through various scenarios so they learn appropriate actions. But those systems work best when they are tailored to the mental states of the individual subject.
Enter HuBar, a novel visual analytics tool designed to summarize and compare task performance sessions in AR — such as AR-guided simulated flights — through the analysis of performer behavior and cognitive workload.
By providing deep insights into pilot behavior and mental states, HuBar enables researchers and trainers to identify patterns, pinpoint areas of difficulty, and optimize AR-assisted training programs for improved learning outcomes and real-world performance.
HuBar was developed by a research team from NYU Tandon School of Engineering that will present it at the 2024 IEEE Visualization and Visual Analytics Conference on October 17, 2024.
“While pilot training is one potential use case, HuBar isn't just for aviation,” explained Claudio Silva, NYU Tandon Institute Professor in the Computer Science and Engineering (CSE) Department, who led the research with collaboration from Northrop Grumman Corporation (NGC). “HuBar visualizes diverse data from AR-assisted tasks, and this comprehensive analysis leads to improved performance and learning outcomes across various complex scenarios.”
“HuBar could help improve training in surgery, military operations and industrial tasks,” said Silva, who is also the co-director of the Visualization and Data Analytics Research Center (VIDA) at NYU.
The team introduced HuBar in a paper that demonstrates its capabilities using aviation as a case study, analyzing data from multiple helicopter co-pilots in an AR flying simulation. The team also produced a video about the system.
Focusing on two pilot subjects, the system revealed striking differences: one subject maintained mostly optimal attention states with few errors, while the other experienced underload states and made frequent mistakes.
HuBar's detailed analysis, including video footage, showed the underperforming copilot often consulted a manual, indicating less task familiarity. Ultimately, HuBar can enable trainers to pinpoint specific areas where copilots struggle and understand why, providing insights to improve AR-assisted training programs.
What makes HuBar unique is its ability to analyze non-linear tasks where different step sequences can lead to success, while integrating and visualizing multiple streams of complex data simultaneously.
This includes brain activity (fNIRS), body movements (IMU), gaze tracking, task procedures, errors, and mental workload classifications. HuBar's comprehensive approach allows for a holistic analysis of performer behavior in AR-assisted tasks, enabling researchers and trainers to identify correlations between cognitive states, physical actions, and task performance across various task completion paths.
HuBar's interactive visualization system also facilitates comparison across different sessions and performers, making it possible to discern patterns and anomalies in complex, non-sequential procedures that might otherwise go unnoticed in traditional analysis methods.
"We can now see exactly when and why a person might become mentally overloaded or dangerously underloaded during a task," said Sonia Castelo, VIDA Research Engineer, Ph.D. student in VIDA, and the HuBar paper’s lead author. "This kind of detailed analysis has never been possible before across such a wide range of applications. It's like having X-ray vision into a person's mind and body during a task, delivering information to tailor AR assistance systems to meet the needs of an individual user.”
As AR systems – including headsets like Microsoft Hololens, Meta Quest and Apple Vision Pro – become more sophisticated and ubiquitous, tools like HuBar will be crucial for understanding how these technologies affect human performance and cognitive load.
"The next generation of AR training systems might adapt in real-time based on a user's mental state," said Joao Rulff, a Ph.D. student in VIDA who worked on the project. "HuBar is helping us understand exactly how that could work across diverse applications and complex task structures."
HuBar is part of the research Silva is pursuing under the Defense Advanced Research Projects Agency (DARPA) Perceptually-enabled Task Guidance (PTG) program. With the support of a $5 million DARPA contract, the NYU group aims to develop AI technologies to help people perform complex tasks while making these users more versatile by expanding their skillset — and more proficient by reducing their errors. The pilot data in this study came from NGC as part of the DARPA PTG
In addition to Silva, Castelo and Rulff, the paper’s authors are: Erin McGowan, PhD Researcher, VIDA; Guande Wu, Ph.D. student, VIDA; Iran R. Roman, Post-Doctoral Researcher, NYU Steinhardt; Roque López, Research Engineer, VIDA; Bea Steers, Research Engineer, NYU Steinhardt; Qi Sun, Assistant Professor of CSE, NYU; Juan Bello, Professor, NYU Tandon and NYU Steinhardt; Bradley Feest, Lead Data Scientist, Northrop Grumman Corporation; Michael Middleton, Applied AI Software Engineer and Researcher, Northrop Grumman Corporation, and PhD student, NYU Tandon; Ryan McKendrick, Applied Cognitive Scientist, Northrop Grumman Corporation.
arXiv:2407.12260 [cs.HC]

NYU Tandon study maps pedestrian crosswalks across entire cities, helping improve road safety and increase walkability
As pedestrian fatalities in the United States reach a 40-year high, a novel approach to measuring crosswalk lengths across entire cities could provide urban planners with crucial data to improve safety interventions.
NYU Tandon School of Engineering researchers Marcel Moran and Debra F. Laefer published the first comprehensive, city-wide analysis of crosswalk distances in the Journal of the American Planning Association. Moran is an Urban Science Faculty Fellow at the Center for Urban Science + Progress (CUSP), and Laefer is a Professor of Civil and Urban Engineering and CUSP faculty member.
"In general, lots of important data related to cities’ pedestrian realm is analog (so it exists only in old diagrams and is not machine readable), is not comprehensive, or both," said lead author Moran, highlighting the gap this study fills. "We know that longer crosswalks pose increased safety risks to pedestrians, but rarely are cities sitting on up-to-date, comprehensive data about their own crosswalks. So even answering the question,‘what are the 100 longest crossings in our city?' is not easy. We want to change that.”
This study's unique contribution lies in its scale and methodology, potentially providing a powerful new tool for city planners to identify and address high-risk areas.
The team analyzed nearly 49,000 crossings in three diverse cities: a European city (Paris), a dense American city (San Francisco), and a less-dense, more car-centric American city (Irvine). To accomplish this, they employed a combination of data sources and techniques.
"We combined crosswalk distance measurements from two different datasets," Laefer said. "The first is from OpenStreetMap, which comes from a community of users who have crowdsourced and built a map of the world."
However, OpenStreetMap data alone wasn't comprehensive enough. "If we had only used OpenStreetMap, we would have been left with a lot of crosswalks missing," Laefer explained. "So we also used satellite imagery tools to measure the remaining crosswalk distances."
Their technique revealed distinct patterns in each urban environment. According to the published paper, the average crosswalk lengths were approximately 26 feet in Paris (.03% at 70 feet or longer), about 43 feet in San Francisco (4.4% at 70 feet or longer), and about 58 feet in Irvine (with about 20% at 70 feet or longer). Crossings over 50 to 60 feet start to show a higher concentration of pedestrian collisions, according to Moran.
The study confirmed a significant correlation between crosswalk length and pedestrian safety in all three cities examined. Longer crosswalks were associated with higher probabilities of pedestrian-vehicle collisions, with each additional foot increasing collision likelihood by 0.8% to 2.11%. Crossings where recent collisions occurred were 15% to 43% longer than city averages.
Moran sees this research as a powerful tool for city planners and policymakers. "The three cities we have mapped now have these datasets, and can evaluate different investments and make informed decisions in pedestrian infrastructure," he explained.
The potential for this research to inform public policy extends beyond these three cities. Moran and his team are planning to scale up their approach to the 100 largest cities in the United States, potentially creating a public resource for exploring crosswalk distances.
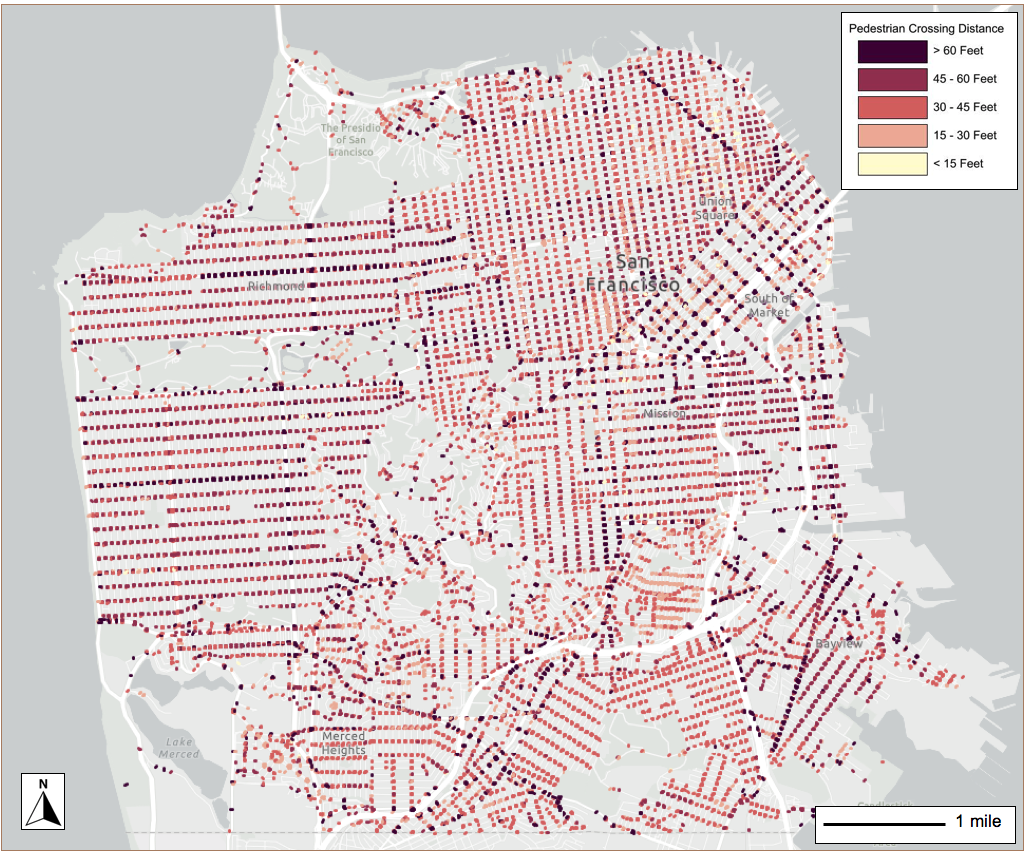
According to Moran, simple measures could significantly improve pedestrian safety on crosswalks. "Small low-tech ways to improve the pedestrian environment can really lead to safety benefits. These can include extending the sidewalks out from each side and putting pedestrian refuge islands in the middle," Moran noted.
This study is part of Moran's broader effort to improve urban transportation. He explains, "I'm trying to make urban transportation safer, more sustainable and more equitable. I use a variety of methods like mining data, satellite imagery and field collection to understand our streets, how they can change, and how those changes can lead to these improved outcomes."
Moran, M. E., & Laefer, D. F. (2024). Multiscale Analysis of Pedestrian Crossing Distance. Journal of the American Planning Association, 1–15. https://doi.org/10.1080/01944363.2024.2394610