
Juliana Freire
,
Ph.D.
-
Institute Professor and Professor of Computer Science
-
Professor of Data Science
-
Co-Director of the VIDA Center

Juliana Freire is an Institute Professor at the Tandon School of Engineering and Professor of Computer Science and Engineering and Data Science at New York University. She served as the elected chair of the ACM SIGMOD and as a council member of the Computing Community Consortium (CCC), and was the NYU lead investigator for the Moore-Sloan Data Science Environment, a grant awarded jointly to UW, NYU, and UC Berkeley. She develops methods and systems that enable a wide range of users to obtain trustworthy insights from data. This spans topics in large-scale data analysis and integration, visualization, machine learning, provenance management, and web information discovery, as well as different application areas, including urban analytics, predictive modeling, and computational reproducibility. She is an active member of the database and Web research communities, with over 250 technical papers (including 12 award-winning papers), several open-source systems, and 12 U.S. patents. According to Google Scholar, her h-index is 65 and her work has received over 18,000 citations. She is an ACM Fellow, a AAAS Fellow, and the recipient of an NSF CAREER, two IBM Faculty awards, and a Google Faculty Research award. She was awarded the ACM SIGMOD Contributions Award in 2020. Her research has been funded by the National Science Foundation, DARPA, Department of Energy, National Institutes of Health, Sloan Foundation, Gordon and Betty Moore Foundation, W. M. Keck Foundation, Google, Amazon, AT&T Research, Microsoft Research, Yahoo! and IBM. She has received M.Sc. and Ph.D. degrees in computer science from the State University of New York at Stony Brook, and a B.S. degree in computer science from the Federal University of Ceara (Brazil).
applied machine learning, provenance management, AI for science, urban analytics, computational reproducibility, and biomedical data harmonization
Education
Ph.D., Computer Science, State University of New York at Stony Brook, 1997
M.S., Computer Science, State University of New York at Stony Brook, 1992
B.S., Computer Science, Universidade Federal do Ceara, Brazil, 1991
Experience
Institute Professor, Tandon School of Engineering, 2022-
Professor, Department of Computer Science and Engineering, New York University, 2011-
Associate Professor, School of Computing and SCI Institute, University of Utah, 2008-2011
Assistant Professor, School of Computing, University of Utah, 2005-2008
Affiliations
Affiliated Faculty, Courant Institute for Mathematical Science
Faculty, NYU Center of Data Science
Awards
- AAAS Fellow, 2021.
- ACM SIGMOD Contributions Award, 2020.
- ACM Fellow, 2014.
- Google Faculty Research Award. Google, 2013.
- IBM Faculty Award. IBM, 2008 and 2014.
- CAREER award. National Science Foundation, 2008.
- ACM SIGMOD Contributions Award, 2020.
- ACM Fellow, 2014.
- IBM Faculty Award, 2014.
- Google Faculty Research Award, 2013.
- NSF CAREER award. National Science Foundation, 2008.
- IBM Faculty Award, 2008.
Research News

Tracking Wildlife Trafficking in the Age of Online Marketplaces
Wildlife trafficking is one of the world’s most widespread illegal trades, contributing to biodiversity loss, organized crime, and public health risks. Once concentrated in physical markets, much of this activity has moved online. Today, animals and animal products are advertised on large e-commerce platforms alongside ordinary consumer goods. This shift makes enforcement harder — but it also creates a valuable source of data.
Every online advertisement leaves behind digital information: text descriptions, prices, images, seller details, and timestamps. If collected and analyzed at scale, these traces can help researchers understand how wildlife trafficking operates online. The problem is volume. Online marketplaces contain millions of listings, and most searches for animal names return irrelevant results such as toys, artwork, or souvenirs. Distinguishing illegal wildlife ads from harmless products is difficult to do manually and challenging to automate.
Institute Professor of Computer Science Juliana Freire is part of a team that is taking on the problem head on, building a scalable system designed to address this challenge. They developed a flexible data collection pipeline that automatically gathers wildlife-related advertisements from the web and filters them using modern machine learning techniques. The goal is not to focus on one species or one website, but to enable broad, systematic monitoring across many platforms, regions, and languages, as well as to develop strategies to disrupt illegal markets.
The team is a multi-disciplinary effort, including Gohar Petrossian, Professor of Criminal Justice at John Jay College of Criminal Justice; Jennifer Jacquet, Professor of Environmental Science and Policy at the University of Miami; and Sunandan Chakraborty, Professor of Data Science at Indiana University.
The pipeline begins with web crawling. The researchers generate tens of thousands of search URLs by combining endangered species names with the search structures of major e-commerce websites. A specialized crawler then follows these links, downloading product pages while limiting requests to avoid overwhelming servers. Over just 34 days, the system retrieved more than 11 million ads.
Next comes information extraction. Product pages are messy and inconsistent, varying widely across websites. The pipeline uses a combination of HTML parsing tools and automated scrapers to extract useful details such as titles, descriptions, prices, images, and seller information. These data are stored in structured formats that allow large-scale analysis.
The most critical step is filtering. While machine learning classifiers can be used for this filtering, training specialized classifiers for multiple collection tasks is both time-consuming and expensive, requiring experts to create training data for each task. Freire’s group developed a new approach that leverages large-language models (LLMs) to label data and use the labeled data to automatically create specialized classifiers, which can perform data triage at a low cost and at scale.
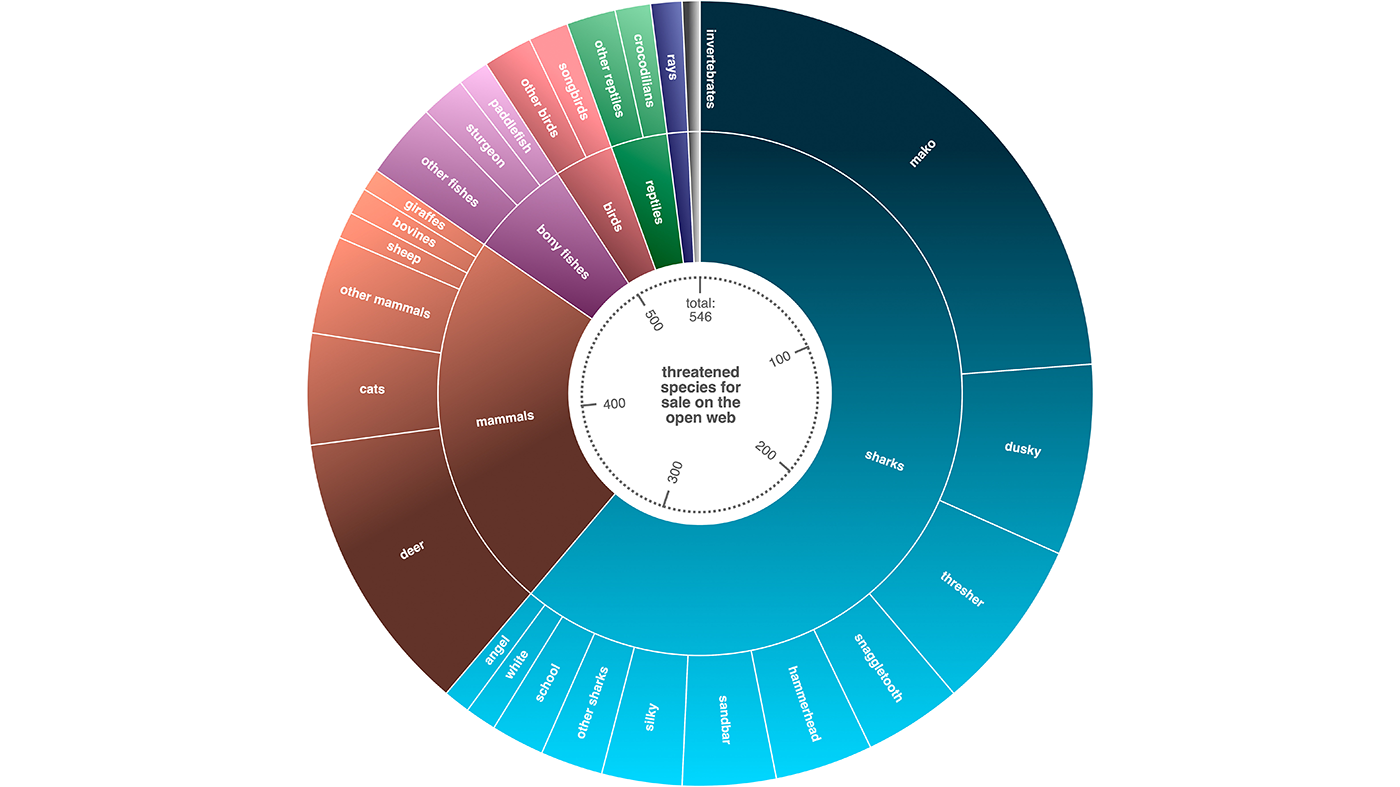
The result is essentially a "model factory:" a pipeline that can automatically produce customized, low-cost classifiers on demand for different triage tasks — different species, different product types, different platforms — without requiring experts to label data from scratch each time.
This research has enabled large-scale data collection to answer different scientific questions and shed insights into different aspects of wildlife trafficking. One analysis of 14,000 reptile leather product listings on eBay showed that crocodile, alligator, and python skins dominated the market. Only about 10 animal-product combinations (such as ‘crocodile bags’, ‘alligator bags’ and ‘alligator watches’ made up about 72 percent of all listings, indicating that the trade heavily focuses on a few luxury items. The analysis of all of the listings from these sites showed that while small leather products were shipped from 65 countries, 93 percent came from 10 countries, with the United States, United Kingdom, Australia collectively accounting for over 3/4th of this market.
Similar data from Ebay on shark and ray trophies reveals that, although the platform has introduced policies to restrict threatened or endangered species, their derivatives are still circulated widely on the platform. Tiger shark trophies accounted for one-fifth of such listings, with asking prices up to $3,000. Over 85 percent of listings were linked to sellers in the United States, suggesting a pipeline from deep sea commercial fishing vessels to the US trophy trade.
This research is also being used to determine what would be the most effective way to disrupt this market. For example, the researchers found that targeting key sellers is effective, but targeting key product types — “alligator watch,” for example — breaks the market of reptile leather products equally effectively, and is much easier to enact at a broad scale.
The authors emphasize that this system is a starting point, not a finished solution. The pipeline is designed to be extensible, allowing future researchers to incorporate better classifiers, image-based analysis, or new data sources. By making the code openly available, they aim to support broader collaboration.
As wildlife trade continues to move online, understanding its digital footprint will be increasingly important. Scalable data collection tools like this one offer a way to transform scattered online listings into actionable knowledge, an essential step toward disrupting illegal wildlife trade in the digital era.
Juliana Silva Barbosa, Ulhas Gondhali, Gohar Petrossian, Kinshuk Sharma, Sunandan Chakraborty, Jennifer Jacquet, and Juliana Freire. 2025. A Cost-Effective LLM-based Approach to Identify Wildlife Trafficking in Online Marketplaces. Proc. ACM Manag. Data 3, 3, Article 119 (June 2025), 23 pages. https://doi.org/10.1145/3725256
Research Centers, Labs, and Groups

Visualization Imaging and Data Analysis Center (VIDA)
We work in the areas of Visualization, Imaging and Data Analysis.

Center for Advanced Technology in Telecommunications (CATT)
Creating economic impact through research, technology transfer, and faculty entrepreneurship.
