
AI & Local News Challenge, Building SimPPL for Local News

Four blocks with various data/information, one regarding upvotes, one regarding users belonging to subreddits, one regarding what users have also engaged with, and one regarding other engagement
The shift towards digital consumption of news introduces more variables for journalists and news organizations to deal with when catering to their readership. The availability of digital trace data provides opportunities for understanding subscriber preferences. In the challenging digital news landscape, many news organizations are producing their work with limited human capital. In such a situation it becomes mission-critical to not only tap into alternative revenue sources like digital ads, but also improve their connection with their readers. But what topics does their audience want to read about? What conversations emerge around their articles? How do these conversations change over time and across platforms? And how can local news do better as the de facto voice of local citizens in many counties?
The challenge in using existing personalization and audience-tracking tools is the need for dedicated personnel, the non-static nature of discourse, and the rapid influx of novel topics into conversations spread across multiple platforms which are hard to track. In a multi-year study of 130 News + AI Technologies by the Knight Foundation,news generation and production technologies outnumbered output monitoring and auditing technologies six to one. We enable local news organizations to visualize the landscape of audiences consuming their articles across different social networks at the click of a button. Our software provides a dynamic picture of the audience that an article reaches via digital channels like Reddit, Twitter, Google, Facebook, and learns their evolving preferences by using bleeding-edge simulation intelligence technology.
The NYC Media Lab’s support of our work via the AI + Local News challenge provided us with the perfect opportunity to transform the probabilistic AI technology underlying SimPPL into a product that can be plugged into journalists' existing workflows. Over the past few months, we built a system that can ingest heterogeneous data from Facebook's CrowdTangle, Twitter's Decahose, and Reddit's Pushshift API to provide systematic insights into audience landscapes on each platform. SimPPL can infer the leaning of content published by a media organization to audit how they shape the public discourse and analyse gaps in coverage for critical topics providing much-needed transparency in public debate. We track custom metrics including multi-platform engagement, enabling local news organizations to personalize their content for existing consumers while improving the diversity of their offerings to reach wider audiences. We leverage probabilistic AI to deliver a customized digital strategy for journalists.
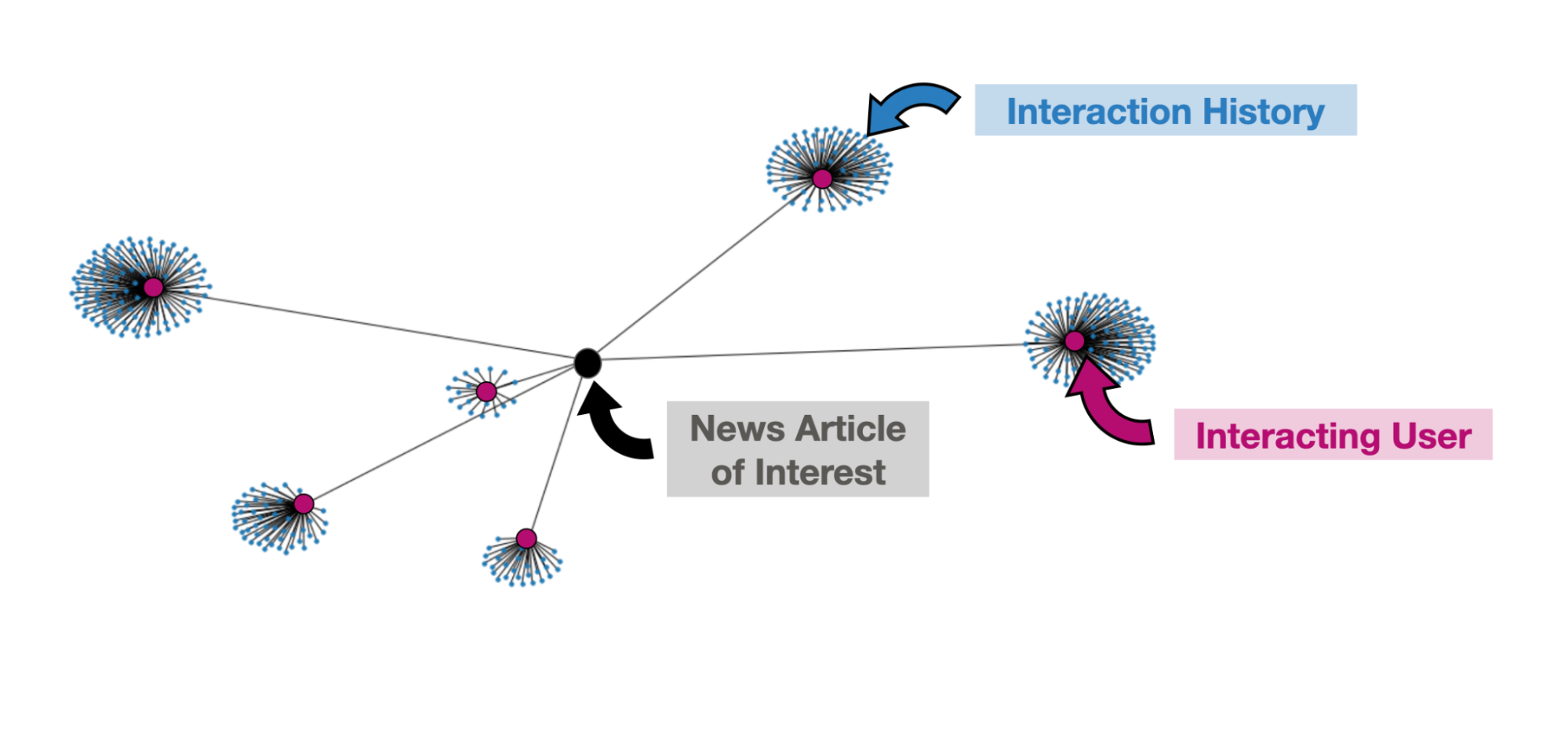
In light of a recent uptick in misinformation, we repurposed our simulation algorithms within SimPPL to model influence operations on social networks, study the content ranking algorithms and their impact on public discourse. Our recent work in collaboration with the Center for Social Media and Politics at NYU and the Torr Vision Group at Oxford was accepted at the AI for Agent-based Models Workshop at one of the top Machine Learning conferences in the world. We are in talks with governmental organizations to employ the social network model in limiting online disinformation and deploying fact-checking interventions.

Our team shares a common vision to help journalists optimize their digital presence. We have built scalable pipelines for information propagation and content analysis in partnership with stakeholders in the social sector. Our team comprises three key members. Harshit Agarwal is a Machine Learning Engineer working on the problems of misinformation, toxicity, spam, abuse, and more at Twitter. Shwetanshu Singh recently received a Masters in Data Science at NYU and joined Leaf Logistics. He also has research experience in Computational Social Science, Data for Good, Human-Computer Interaction, and NLP having worked with the New York Times and the NYC Media Lab. For my part, I am a Ph.D. candidate at NYU Data Science and visiting researcher at Oxford, currently interning with the Civic Integrity team at Twitter. I previously interned with Adobe Research, and worked in particle physics and machine learning at CERN. SimPPL also benefitted from helpful feedback from the Unicode Research Community, some of whom are also helping us in our pilot project with the VTDigger and to develop the platform further.

